Physiology News Magazine

Standard setting for physiology
In an era of increased student appeals and litigation, the science of setting standards for educational attainment has never been more important. Is it time to reassess our approach in physiology?
Features
Standard setting for physiology
In an era of increased student appeals and litigation, the science of setting standards for educational attainment has never been more important. Is it time to reassess our approach in physiology?
Features
Harry Witchel
Brighton and Sussex Medical School, UK
https://doi.org/10.36866/pn.89.26
Academics have always maintained standards of achievement for their examinations, such as marking on a curve, or having a pass mark of 50. The General Medical Council (GMC), in their 2009 document ‘Tomorrow’s Doctors’ has outlined the need for “valid and reliable methods of standard setting” in UK medical schools. The passing grade of a test cannot be decided arbitrarily; it must be justified with empirical data. At this year’s annual meeting of The Physiological Society in Edinburgh, an Education and Teaching (ET) theme symposium took place on ‘Standard setting in physiology assessment: what is it and does it matter?’ It considered the role of standard setting, the opportunities it provides, as well as its weaknesses.
Standard setting is a process that a group of test developers use to determine a cut score (e.g. the pass/fail borderline) for a given assessment. It is a systematic, externally justifiable process for reaching a consensus on professional standards. Standard setting ‘operationalises’ the ‘minimally competent’ standard of authorizing entities (such as the GMC) into a test score for a specific examination. Although standard setting incorporates methodologies, it is fundamentally a value judgement, and it often involves some kind of a priori estimation.
Standard setting is more justifiable than norm referencing. Norm referencing (or grading on a curve) determines grade boundaries based on a normal distribution of other students’ performance (e.g. the top 10% of the class receives an A). Norm referencing compares students to each other rather than to an absolute criterion, so it may pass inferior students if they are among a weak cohort. Likewise, deciding upon a pass mark of 50 year after year assumes that the examination questions are the same difficulty from one year to the next, despite changes in staff and curriculum material. The downside of standard setting is that the process consumes time, money, and other resources.
Methods for standard setting are categorized as relative methods or absolute methods. Relative methods compare the students’ performance to each other, while absolute methods refer to an external reference point. Absolute methods are preferable for high stakes competency tests, while relative processes are better for distributing a limited number of opportunities. Most absolute methods usually require much more time because the external standards are harder to reference and most aspects of the examination have to be considered piecemeal.
An example of absolute standard setting is the Angoff method. Test questions are sent in advance to a panel of subject matter experts, comprising at least six to eight experts who are familiar with the material and with the expected performance of the student cohort (Norcini, 2003). Each member of the panel predicts for each question the expected score of a minimally competent student. The panel then meets to discuss their estimates on a question-by-question basis, and panel members may readjust their scores as they move toward consensus. The cut score (i.e. a score that is minimally competent for the entire test) is calculated from the predicted difficulty scores for the individual questions.
Rationale: What are the risks of not standard setting?
In an era of increased student appeals and litigation, standard setting makes the decision process of test outcomes legally defensible. Law courts can accept the validity of subjective judgements, so long as these are reached by an appropriately qualified group (and are not discriminatory). Standard setting is based on expert judgement informed by data about examinee performance. This makes it transparent, easy to institute, and easy to explain. The value of standard setting is supported by a body of evidence (Norcini & Shea, 1997).
Standard setting is particularly important for assuring consistency, particularly from year to year. Standard setting maintains standards when a particular assessment is too easy. Likewise, a new module leader may compile an assessment that is too difficult and standard setting can correct for that too. This means that standard setting is fairer over the long term. While marking on a curve (norm referencing) also corrects for tests that are too difficult, some student cohorts are genuinely better, and others are genuinely worse; standard setting pitches the cut score toward an a priori standard.
By being an explicit process, standard setting reinforces the fit of the assessment content to the learning outcomes. This is true for both the learning outcomes of the curriculum, and those of any validation body such as the GMC. From the test developers’ perspective, standard setting can allow examiners to recognise confusing questions, problematic assessments or poor teaching; these are mooted when the students’ performance on a question differs from predicted performance. Particularly because standard setting predicts the level of a minimally competent student, when the mean student score for an item (or for a test) is below the expected score for a minimally competent student, it highlights that item. This divergence of standard setting from student performance prioritises investigating this item (or assessment) for more serious problems, although the problem may be only that the standard setting panel made a poor prediction.
Challenges and pitfalls of standard setting
Students complain when too many of them fail an exam. Over-estimating student performance and thus failing too many students is an intermittent problem, and one standard setting method (Hofstee, see below) specifically prevents this by polling the expert panel on the maximum and minimum acceptable failure rates, which is incorporated into the determination of the cut score.
The literature on standard setting stresses the importance of selecting the right experts for the panel — both in quality and quantity. Subject matter experts should be experts in a field related to the examination, although there is a small research literature showing that sometimes the standard setting results from a panel of recent medical graduates is more ‘credible’ than from a panel of assessment writers (Verhoeven et al. 2002). That result may be explained because ideal panel members should be familiar with both examination methods and the level of candidates; finding faculty experts who understand, and agree on, what a first year medical student should know versus what a third year medical student should know may not be as accurate as polling fresh graduates, who remember the difference quite well. Similarly, subject matter experts from a single discipline may feel unqualified to predict many items in assessments from a multi-disciplinary systems-based course. Another approach is to use only multidisciplinarily trained experts, such as medical faculty — some medical schools include their GP facilitators in standard setting, although this is a costly option.
Even when the panel chosen has the requisite expertise there can be biases in judgement. In multidisciplinary panels, experts often see questions in their own discipline as easier and more essential than other disciplines. Finally, in most panels there are hawks and doves, whose standards for passing seem consistently quite high or low.
While most academics are prepared to put time into a process if it results in a better education or higher standards, panel members are less enthusiastic if the process or its results seem confusing, arbitrary or unmoored from actuality. The literature often mentions that panel members find estimating the performance of minimally competent (or “the borderline candidate”) difficult. To combat this, some panels begin with a discussion of what is a borderline candidate. Furthermore, it is complex, time-consuming, and costly to assemble a large panel of high ranking experts to meet for hours, especially when a resit exam should (for reasons of parity) be standard set at the same time as the main exam — thus doubling the meeting length. Some departments are experimenting with online methods to gather the expert’s predictions, such as Survey Monkey.
The process of standard setting highlights the fact that most medical schools use a single examination to test both for competence and for excellence (e.g. class rank). Some standard setting methods are most suitable for multiple choice questions (e.g. the USMLE step 1), where there is a clear need for data to determine how well students should perform on a particular test item (because some of the difficult questions were ‘confusing’ – Case & Swanson, 2012). When searching for excellence, which incorporates innovation, multiple choice type questions are inappropriate; likewise, the assessments best suited for detecting excellence may in some cases be completely irrelevant for determining competence. Thus, with some methods of standard setting (e.g. the Cohen method), mixing core with non-core material on an assessment creates a theoretical difficulty — borderline students will have spent exam time attempting difficult questions that are above both their abilities and the requirements. Oxford and Cambridge routinely apply to their medical cohort two separate assessment systems: one for competence (MCQ based) and one for excellence (essays).
Strengths and weaknesses of the most common methods for standard-setting
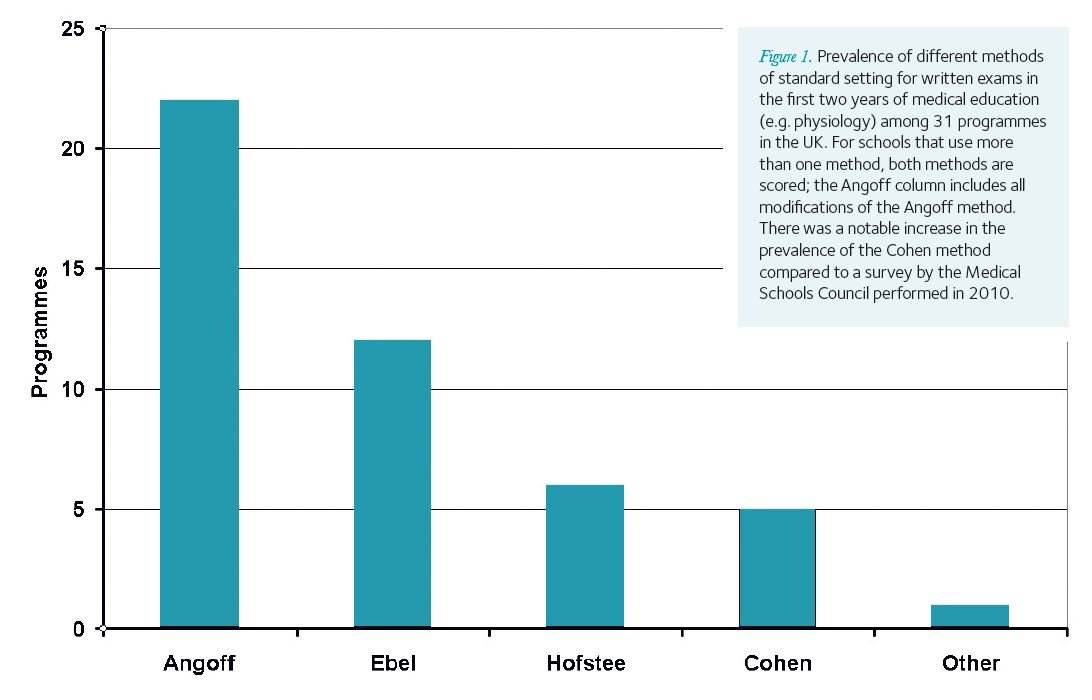
There is no gold standard for standard-setting; different methods will produce different pass scores (Downing et al. 2006). We surveyed 31 UK medical schools as to which standards setting procedure they used for written exams (e.g. physiology in the first two years); there is currently no consensus among UK medical schools (see Fig. 1), although the Angoff method and its modifications remain the most prevalent.
A recurring problem for the Angoff method is “regression to the mean” (Buckendahl et al. 2002). The cut scores change only slightly as the difficulty of the assessment increases, and in many cases the cut score is often the same number year on year irrespective of the examination’s true difficulty; yet, producing the cut score can require a ‘tiresome’ amount of staff work (Norcini, 2003). When the Angoff method makes errors (unexpectedly high or low failure rates, expert estimates that diverge from student performance), usually this is attributed to the composition of the expert panel (too few experts, or incomplete expertise). During The Physiological Society 2012 symposium, Prem Kumar organised a demonstration implying that for short answer questions the modified Angoff method (rather than the composition of the expert panel) may be at fault.
The Ebel method has the advantage that it does not require the experts to put a number to the difficulty of the question; instead, they rate questions as easy, medium or difficult. This makes rating easier for the experts, and it may help with the dove/hawk problem as well. The Ebel method also asks panel members for an estimation of whether the item is testing for essential information (i.e. is it relevant for core competence); items are rated as essential, important, or acceptable. The cut score is calculated from the difficulty and relevance ratings.
The Hofstee method is a compromise method, between absolute and relative, in which the experts review the assessment in detail and then answer: what are the minimum and maximum acceptable cut scores? What are the minimum and maximum acceptable failure rates? Student performance is then compared to the experts’ answers to determine a cut score. The advantages of the Hofstee method are that it is easy to implement, and that the experts (especially educators) are comfortable with the decisions. The main disadvantage is that the cut score arising from the Hofstee calculation may not be within the experts’ range, so Hofstee is not typically the first choice in a high stakes assessment.
The Cohen method is a relative method that calculates the final pass/fail boundary on a percentage of the highest performers’ scores, e.g. 0.65 x 90th centile. The highest performers in the class are seen as a reliable index of exam difficulty – their performance is considered consistent. Examiners feel comfortable when running the Cohen method because it does not involve estimating the performance of a ‘borderline candidate’. It differs from other relative methods because the pass-fail boundary does not depend on the performance of the failing/weakest students. However, as with other relative methods, it tends to be eschewed in high stakes assessments. In our survey of UK medical schools, the prevalence of the Cohen method has increased compared to a survey done two years ago by the Medical Schools Council.
Conclusion
Despite the extra work and the intermittent challenges with its execution, physiologists assessing on medical programmes are instituting standard setting in good faith. Attempts are being made to understand the repercussions of each method of standard setting, and the resulting opportunities for improving our assessments and teaching are being pursued.
References
Buckendahl CW, Smith RW, Impara JC & Plake BS (2002). A comparison of Angoff and Bookmark standard setting methods. Journal of Education Measurement 39(3), 253-263.
Case SM and Swanson DB (2012). Constructing Written Test Questions for the Basic and Clinical Sciences, Third Edition. National Board of Medical Examiners: Philadelphia, PA
Downing SM, Tekian A & Yudkowsky R (2006). Procedures for establishing defensible absolute passing scores on performance examinations in health professions education. Teaching and Learning in Medicine 18(1), 50–57.
Norcini JJ (2003). Setting standards on educational tests. Medical Education 37, 464–469.
Norcini JJ & Shea JA (1997). The credibility and comparability of standards. Applied Measurement in Education 10(1), 39-59.
Verhoeven BH, Verwijnen GM, Muijtjens AMM, Scherpbier AJJA & Van Der Vleuten CPM (2002). Panel expertise for an Angoff standard setting procedure in progress testing: item writers compared to recently graduated students. Medical Education 36(9), 860–867.
Meeting Notes: Physiology 2012
Education and Teaching (ET) theme symposium
Standard setting in physiology assessment: what is it and does it matter?
4 July 2012, Edinburgh, UK
For many attendees this was the first time they discussed how standard setting was performed outside of their own universities, making this ET theme session both useful and thought-provoking. First, Prem Kumar from University of Birmingham outlined the various types of standard setting, and explained their rationales, which varied from the defensible to the feasible. He later presented a talk and demonstration entitled, “Can we use the modified Angoff method for short answer questions.” He proposed that the widespread modified Angoff methods may be particularly suitable for multiple choice formats and for those assessments that gauge a readily agreed upon competency; however, there might be a problem when applying these kinds of methods to short answer questions. Attendees formed the expert panel to judge two questions (one known to be more difficult based on past student results). The demonstration showed that in a room full of physiologists, all of whom are experienced teachers, there was still regression to the mean. As this outcome could not be attributed to the composition of the expert panel, the problem may be fundamental to the modified Angoff method.
Judy Harris from University of Bristol gave a presentation with an interactive demonstration. “Using the Ebel method for standard setting” allowed groups of the attendees to try out the Ebel method’s two-way rating system based on importance and difficulty. In the symposium, attendees found the process of rating without numbers amenable, and the results were consistent with intuitive expectations about the items rated; the ratings varied by group, so “hawks and doves” were still present.
John Morris (co-authored with D Young and R Perera) at University of Oxford presented “Standard setting for core biomedical assessments: Oxford’s experience with a new method.” At Oxford, assessment of wider reading and understanding is done by essays in which students have a choice, but core information (relevant to minimal competence and the requirements of the GMC) is tested by an automated system with questions based on single best answer or extended matching format. One criterion they sought from standard setting was to separate the variance in exam scores due to the difficulty of the examination from that due to the performance of the students. Their results reaffirmed the fundamental premise of the Cohen method, which is that the standard of a top cohort of students is consistent from year to year and from examination to examination.
Stewart Petersen from the University of Leicester gave a presentation incorporating his experiences as part of inspection teams acting on behalf of the GMC, and David Lewis from the University of Leeds led the subsequent discussion session.
